overview
This session focuses on the history and perspectives of developing AI techniques, from 1950's Turing Test until today's large language models.
summary
- intro
- intro
- symbolic intelligence
- symbolic intelligence
- connected intelligence
- connected intelligence
- today
- today
- conclusion
- conclusion
- project check-in
- project check-in
intro
artificial intelligence
welcome!
plan for the day
- the history and hypes of AI
- AI through rules
- AI through examples
- HTML layout and JavaScript
symbolic intelligence
question
do you think we should use an AI software in the court room?
- horrible idea (not good at judgment, only repetitive)
- helpful bureaucracy, lowers barrier of entry
- only in very simple cases
- humans are not always better than AI
- do you consider justice maths or something beyond?
- garbage in/garbage out
- no accountability
what is AI?
turing and his test
the imitation game, 1950
can one tell apart a man and a woman? a human and a machine?
- the difference between being and appearing
- the role of education
In the process of trying to imitate an adult human mind we are bound to think a good deal about the process which has brought it to the state that it is in. We may notice three components:
(a) The initial state of the mind, say at birth,
(b) The education to which it has been subjected,
(c) Other experience, not to be described as education, to which it has been subjected.
Turing starts by asking the question of whether we could ever tell apart a robot from a human, if we could only talk to them via a computer interface (i.e. texting). This is the first standard of intelligence that is put forward.
hype #1 - symbolical

1956 in dartmouth, joseph mccarthy
highly mathematical approach
culminates in SHRDLU, a language interface for spatial recognition (1968-1970)
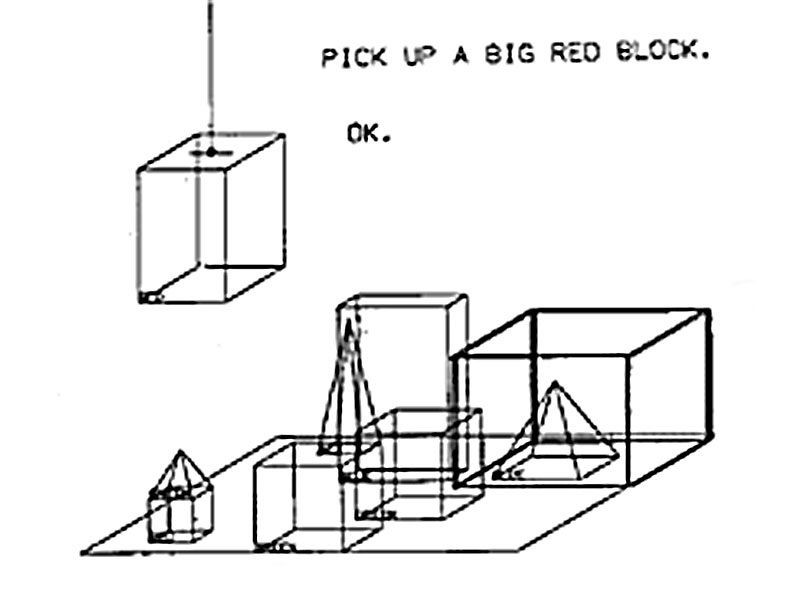
The first approach to AI starts in 1956, with the coining of the term "Artificial Intelligence" by a bunch of mathematicians at Dartmouth. They assume that one can represent the mind through abstract concepts and connections.
criticism #1 - eliza

joseph weizenbaum, 1964
ELIZA is one version a single chatbot
- ELIZA: how are you feeling today?
- PATIENT: i'm feeling sad
- ELIZA: why are you feeling sad?
- PATIENT: because of some dumb thing
- ELIZA: what kind of dumb thing?
would you use a chatbot as a therapist?
- not too customized (pattern matching)
- data privacy issue, corporation links
- therapists provide empathy, enable projection
- supplement, and not replace
- less responsibility
- mixed feelings, has some knowledge, but goes loop
the difference between choice and judgment
[Politicians in the Pentagon] wanted to constantly find laws with which political and historical facts could be explained and predicted, as if they were made with the same necessity and thus reliability as the physicists of natural events used to believe in the past.
An extremely irrational trust in the predictability of reality has become the leitmotif of decision-making.
there are things that machines ought not to do
The first criticism of this approach comes from Joseph Weizenbaum who, in his book Computer Power and Human Reason makes the difference between things that require choice, which a computer can do, and things which require judgment, which a computer cannot do. This is because the former is only calculation, while the latter is value based.
He intends to show that machines can never be truly conscious by building one: the first chatbot, ELIZA. However, the illusion of intelligence remains and psychiatrists across the country reach out to him to use the robot in therapy.
winter #1
turns out, computers don't work so well in the real world
1965s - 1975s
These debates take place exclusively in academia, where there is quite a lot of computing power to do these intelligence experiments. However, the private sector does not benefit from it, and the hype dies out.
hype #2 - expert systems
increase in data and usable languages enable commercial applications
- SABRE (automated travel agent) - 1976
- MAVENT (mortgage and lending compliance automation) - 1980
- HFT (high frequency trading) - 1983
The second wave results in expert systems, which require more computing power, and in the formalization of complex rule systems, such as finding the cheapest airline ticket, calculating someone's mortgage, or deciding to buy or sell stock. Some of these systems still exist today, but the normalization of their use makes them less prone to being qualified as "AI".
criticism #2 - chinese room
a system based on rules is not necessarily conscious

The second criticism aims at the fallacy of representing knowledge as rules. John Searle proposes an experiment to illsutrate it: the chinese room paradox
winter #2
logic as knowledge representation peaks without hardware
logic representation becomes a cathedral of rules, and crumbles
hype #3 - big computers
MITI, IBM build very fast computers, still operating on logic

kasparov vs. IBM Deep Blue, 1996-1997
The summit of the logical/big hardware approach is when IBM builds a computer which manages to beat Kasparov, chess grandmaster. However, one might think it's only a fairly restricted conception of intelligence.
connected intelligence
meanwhile

frank rosenblatt pretending not to be confused by his perceptron, 1950s
There is another alternative to the development of AI: rather than logical of few, complex concepts, one can also take a huge amount of somewhat simple concepts.
sensing and thinking
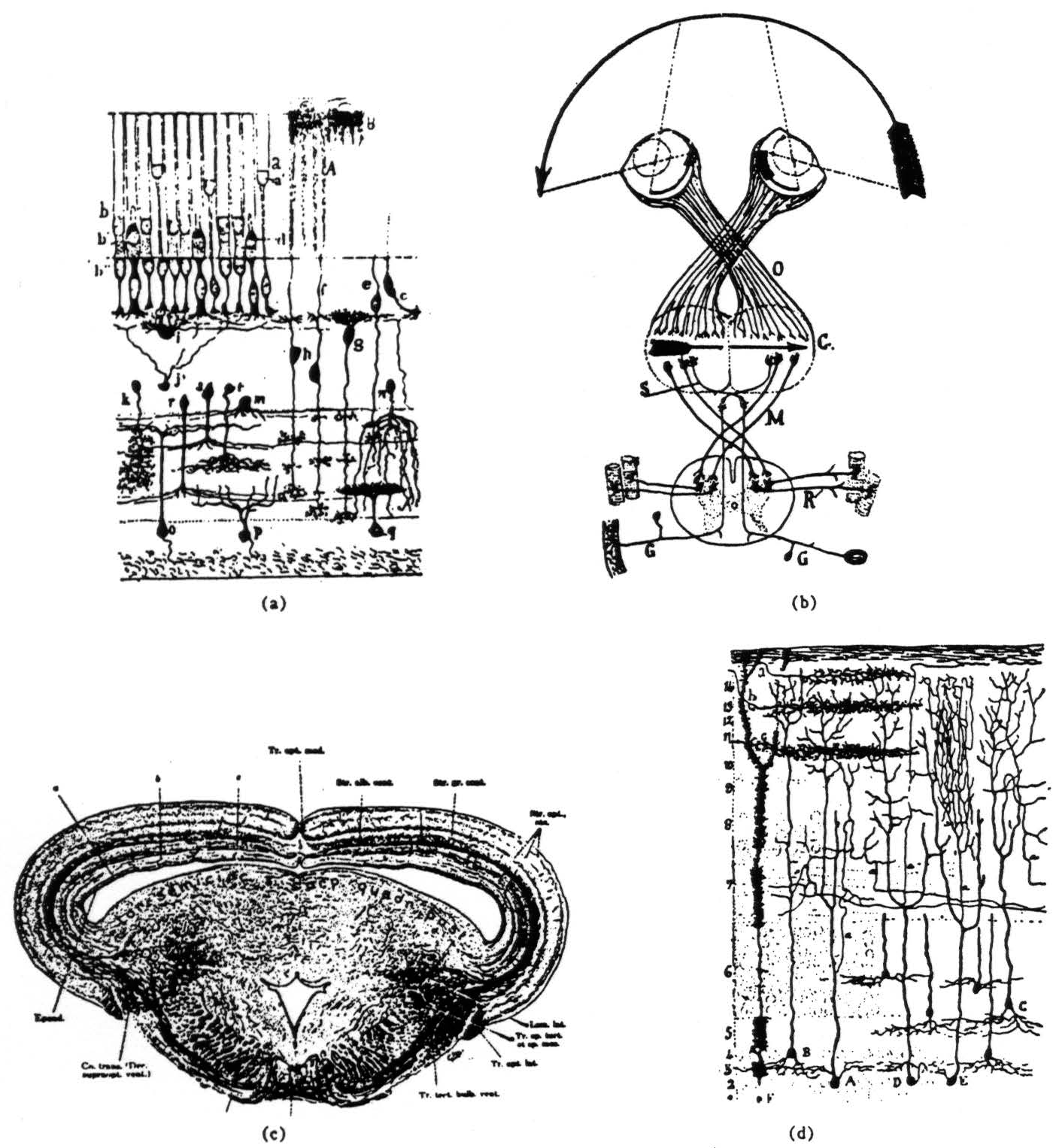
what the frog's eye tells the frog's brain, 1959
warren mccullough, walter pitts
so what about neurons? can you represent thought just through single perceptive units?
but we still need fast computers and a lot of input
Additionally, fundamental research in neuroscience shows that not all intelligence happens in the brain (the illusion of "i think therefore i am" philosophical tradition). Particularly, some visual processing of objects happens directly in the eye rather than in the brain.
hype #4 - big data

mnist dataset - from the us bureau of census
neural networks start to perform super well (end of 2000s)
instead of inductive reasoning (i.e. knowing the rules beforehand)
you go for deductive reasoning (i.e. you figure out the rules as you go)
machine learning, deep learning, convolutional neural networks, stable diffusion, etc.
essentially deciding on a series of weights given a certain data set, and then checking with a verification dataset.
deep learning and gans
deep learning can train itself

lee sedol loses to alpha go, 2016
The technique is so successful that it manages to beat the best human player at Go (at the time, the IBM computer that was the best at chess could barely beat a professional Go player). Still, the standard for intelligence is still that of a well-defined ruleset.
Learn more about how deep learning works here
today
large language models
the real name of chatGPT
"As long as you can turn it into a vector, you're OK"
Yann LeCun, Chief AI Scientist at Meta
word2vec
a vector is a series of numbers, that can represent a position in space (space can go beyond 3 dimensions)
By combining this approach with a representation of text as a set of vectors (i.e. putting words in space), we can start to extract higher-level features (i.e. meaning) from a raw corpus of common crawl
reflecting the dataset
culturally-encoded datasets: moral machine
Now that we work with masses of data, we have new problems: biased data that reflect the inequalities and injustices in society. There are multiple ways to deal with it:
- changing the dataset to include more representational data
- training the AI to nudge it towards a non-biased response
nlp
natural language processing tasks
- translation
- emotion detection
- task comprehension
- language generation
the transformer architecture
Attention is all you need, Google, 2017
not just where words are compared to all the different other words, but where they are in a sentence
In 2017, Google releases a paper which combines this word-to-vector representation with a linear development: basically, they have an algorithm which can guess the next word in a sentence, and turns out it's very effective!
the role of presentation
autocomplete is old AI -> over a long period of time, small increments, embedded in the everyday
chatGPT is new AI -> radical break, huge jump in abilities, stand-alone application
how do you use chatGPT?
- finding bibliography
- develop basic arguments
- rephrasing readings
- initiating writing prompts
- writeup in style / copyediting
- feel good about myself
gpt is the proof that reading makes you intelligent
and we use it to stop reading
LLMs and jobs
to what extent do you think is AI going to take jobs?
when you behave like a machine, you are liable to being replaced by a machine
-> qualified workers in factories replaced by physical machines
-> qualified workers in offices replaced by cognitive machines
AI Act
- limits AI use to different applications, based on risk level (EU)
companies need a massive amount of process in order to produce a "correct" AI
internal safety checks and procedures
carbon footprint:
- training GPT4 is the equivalent of 600 transatlantic flights
- the increase has been 300,000x from 2013-2023
- LLM query is 4-5x higher than a search query
conclusion
a new hype cycle?
- things would change but not too much
- tech companies decide what ethics are
- if you make highly patterned cognitive work, you're in trouble
- human-machine cooperation tends to yield better results than machine alone
- mitigations are happening at both the process and application level, but should not detract from important issues
project check-in
commentary
due date: tonight at 11:59pm, on the URL that is listed on the spreadsheet.
- a page on your website (e.g.
commentary.html) - using multiple
<p>tags, and<a href="">